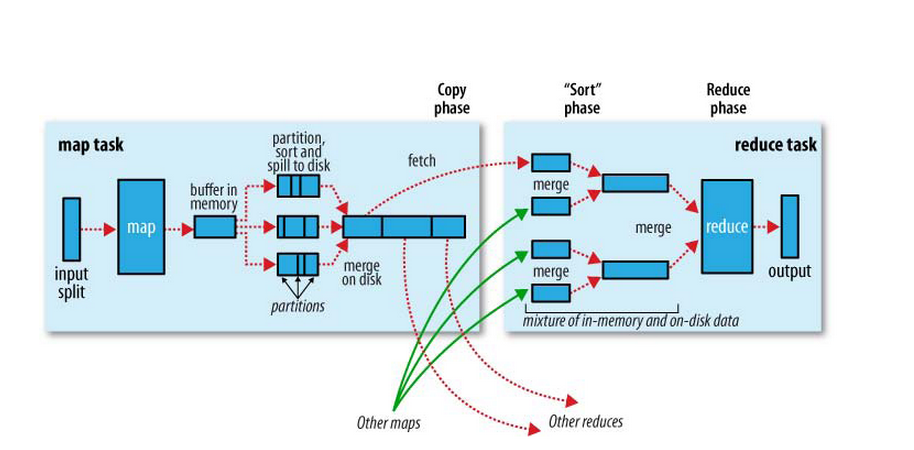
Map阶段
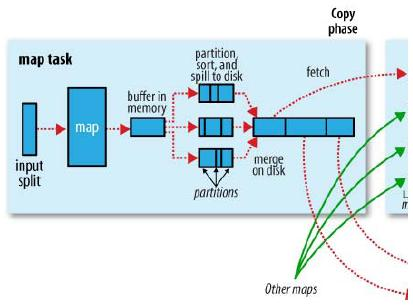 map首先从job input dir的位置开始加载文件,经过map函数之后计算的结果会先写入buffer in memory中,每一个map对应一块MapOutputBuffer,即图中的buffer in memory,这个memory得大小由一个著名参数io.sort.mb决定,默认为100MB,在提交的job Configure中或者jobhistory的xml配置都可以看到这个参数。
map首先从job input dir的位置开始加载文件,经过map函数之后计算的结果会先写入buffer in memory中,每一个map对应一块MapOutputBuffer,即图中的buffer in memory,这个memory得大小由一个著名参数io.sort.mb决定,默认为100MB,在提交的job Configure中或者jobhistory的xml配置都可以看到这个参数。
<property>
<name>io.sort.mb</name>
<value>100</value>
</property>
但是由于buffer有限,当buffer达到了io.sort.spill.percent(默认80%)之后就对buffer in memory中的数据进行sort和spill,全部将计算结果写入磁盘后,之后根据spill后产生的多个partition进行Merge,这里有一 个可以并发控制一次加载多少个partition的参数io.sort.factor(默认为10),cobiner的函数执行就在Spill和 Merge过程里,
<property>
<name>io.sort.spill.percent</name>
<value>0.80</value>
</property>
<property>
<name>io.sort.factor</name>
<value>10</value>
</property>
最后就是压缩,对mapred.compress.map.output压缩会非常有力减少对磁盘的写入。
<property>
<name>mapred.map.output.compression.codec</name>
<value>org.apache.hadoop.io.compress.DefaultCodec</value>
</property>
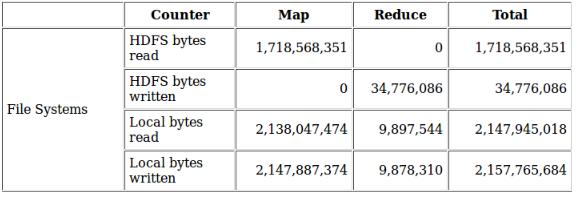
未压缩:
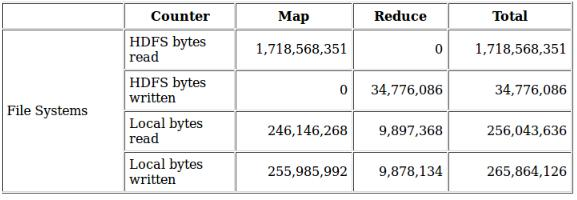
压缩:
Reduce阶段
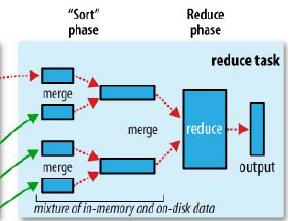 reduce分为三个阶段 copy -> sort -> reduce ,由于map节点产生的partition可能会分不到不同的reduce中进行,所以理论上从第一个map结束开始,reduce就可以开始做shuffle了,这里有个并发copy的参数:
reduce分为三个阶段 copy -> sort -> reduce ,由于map节点产生的partition可能会分不到不同的reduce中进行,所以理论上从第一个map结束开始,reduce就可以开始做shuffle了,这里有个并发copy的参数:
mapred.reduce.parallel.copies(default 5)
即同时从5个map目录下载数据。reduce如果经过mapred.reduce.copy.backoff时间还没有下载成功,比如map服务器异常,网络异常等原因,如果网络本身比较繁忙,就可以调整这个参数,减少误判断次数。 在本地copy结束后,会对copy结果进行merge,io.sort.factor这个参数在这里也发挥作用了,来控制一次加载多少个文件做merge。 当reduce下载了所有map partitions文件,之后会进行快速的sort,这个时间一般会比较短,因为很多partition边下载就边做排序了,之后就到了reduce实际的计算函数。 mapred.job.reduce.input.buffer.percent这个参数是指,有多少sort完成后reduce计算阶段用来缓存数据的 百分比,这个值是指sort后的内存一般不再使用,而是直接清除内存后从磁盘加载,这个参数有点蹊跷,理论上减少一次磁盘读取的优化,为什么hadoop 默认是关闭的,调整这个有可能导致sort速度变慢,还是有什么其他考虑?