spark streaming是spark核心api的一部分,它具有可扩展,高吞吐,容错等特点,所以在处理流失数据时是非常有用的。它可以从kafka,flume,twitter,zeromq,kinesis或者tcp中读取数据经过一系列的高阶函数如map,reduce,join和window处理,最后将处理完成的数据放入文件系统,数据库或者Dashboard。 spark streaming中的DStream表示一个连续的数据流,DStream可以通过kafka等数据源创建而来或者通过在其他的DStream上使用高阶操作而来,其实DStream也就是一系列的RDD。
例子
下面的例子是计算从tcp接收到的数据中的单词个数。 首先需要导入streaming需要的类,StreamingContext是使用streaming的入口,下面创建了一个2个线程和每隔1秒进行批处理的StreamingContext类:
import org.apache.spark.\
import org.apache.spark.streaming.\
import org.apache.spark.streaming.StreamingContext.\_
// Create a local StreamingContext with two working thread and batch interval of 1 second
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
接下来既可以通过StreamingContext来创建DStream(也就是监听tcp进行数据接收):
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("localhost", 9999)
接下来将接收到的每行数据按空格分隔:
// Split each line into words
val words = lines.flatMap(\_.split(" "))
上面使用flatMap创建了一个新的DStream,接下来就可以统计每个单词的个数了:
import org.apache.spark.streaming.StreamingContext.\
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(\ + \_)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
上面代码首先将每个单词变成(word,1)形式,然后通过reduceByKey将word相等的pair的个数相加。最后打印结果(这个结果也只是每秒(通过最开始程序指定)接收到的数据的统计结果)。 由于spark是懒加载的,所以上面的程序并不会真正进行计算,待执行到下面代码后程序才会从头开始处理程序:
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
注意:
DStream
DStream在spark中表示一系列的数据流,其中的内容就是一个个的RDD数据集,在DStream上的操作会被转化为操作其内部的RDD。
Input DStream
input DStream是从各种数据源接收到的流,每个input DStream都有一个receiver对象用来从数据源接收数据并且将数据存放在内存中。所以每个input DStream只会接收一个单独的数据流,但可以创建多个input DStream以便能并行的接收到多个数据流。
接收器是作为一个长时间运行的任务运行在spark的worker或executor中,因此一个接收器会占用一个cpu,所以spark streaming应用需要分配足够的cpu来处理接收到的数据。
注意:
基本数据源
上面例子使用了tcp作为数据源,另外还有很多其他的基本数据源:
streamingContext.fileStream\[keyClass, valueClass, inputFormatClass\](dataDirectory)
spark streaming会从dataDirectory文件夹读取所有文件(除该文件夹中子文件夹里的文件外),需要注意这些文件必须有相同的数据格式;这些文件必须以原子移动或重命名的方式在这个文件夹内创建;一旦这些文件被创建,那么它就不能被改变了,所以以后在这些文件里添加新的内容时这些新的内容将不会被读取。
高级数据源
高级数据源包括之前提到的kafka,flume,twitter等,比如要使用twitter的数据流创建DStream,需要做以下事情:
1.将spark-streaming-twitter_2.10添加到sbt或maven中
2.导入TwitterUtils类并使用TwitterUtils.createStream(sparkStreamingContext)方法来创建DStream
3.生成jar包部署改程序
DStream转换
DStream支持的常见转换方式有以下几种:
| 转换方法 | 意义 |
|---|---|
| map(func) | 将源DStream中的每一个元素经过func函数的处理并返回一个新的DStream |
| flatMap(func) | 类似map,但每个元素会返回0或多个元素 |
| filter(func) | 返回func函数返回true的元素组成的DStream |
| repartition(numPartitions) | 将DStream重新进行分区 |
| union(otherStream) | 返回包含源DStream和otherDStream的新DStream |
| count() | 返回源DStream中每个RDD数据中的元素个数 |
| reduce(func) | 使用func函数(该函数接受2个参数并返回一个结果)计算源DStream中的每个RDD数据的元素 |
| countByValue() | 返回DStream中每个元素的出现次数 |
| reduceByKey(func,[numTasks]) | DStream格式为(K,V)格式,通过func函数的处理返回(K,V)格式数据。在本地模式numTasks的默认值为2,在集群模式下默认值为spark.default.parallelism配置的值 |
| join(otherStream,[numTasks]) | 由(K,V)和(K,W)返回(K,(V,W)) |
| cogroup(otherStream,[numTasks]) | 由(K,V)和(K,W)返回(K,Seq[V],Seq[W]) |
| transform(func) | DStream中的每个RDD通过func函数的处理转变为新的RDD |
| updateStateByKey(func) | 改变DStream中key的状态 |
下面详细讲下最后两个装换方法:
UpdateStateByKey
这个方法允许获取数据新的状态,需要以下两个步骤:
1.首先需要定义数据的初始状态:状态可以为多种数据类型
2.定义状态改变函数:该函数利用数据之前的状态和stream中新的值返回新的状态
下面的例子中状态改变函数将计数作为状态,其中pairs DStream是(word,1)格式:
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}
val runningCounts = pairs.updateStateByKey[Int](updateFunction _)
上面的例子中每个word都会传递到状态改变函数中处理,传递的newValues就是一系列的1,所以上述例子也可以用来计算每个word的次数。
转换操作
转换操作允许DStream执行RDD-RDD函数,转换操作可以用于任何RDD上。例如当你想实时将输入数据与之前计算好的数据进行合并执行filter操作,可以:
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information
val cleanedDStream = wordCounts.transform(rdd => {
rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning
...
})
窗口操作
spark streaming也提供了窗口计算,它允许在滑动窗口上的数据进行转换操作。下图介绍了滑动窗口:
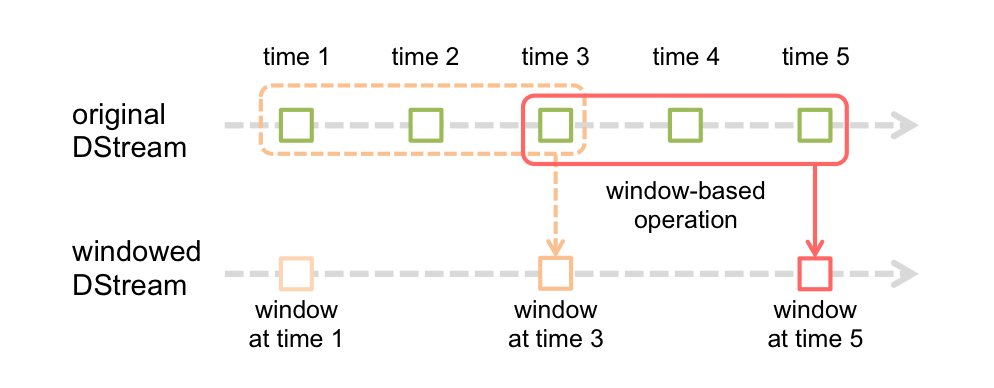 上图显示,每个时刻窗口会在源DStream上滑动,在这个窗口里的RDD会被合并和进行相应的操作生成窗口DStream。在上图的情形下,相关操作会在最后3个时间单元的数据上进行,并且滑动2个时间单元,所以窗口操作需要两个参数:
上图显示,每个时刻窗口会在源DStream上滑动,在这个窗口里的RDD会被合并和进行相应的操作生成窗口DStream。在上图的情形下,相关操作会在最后3个时间单元的数据上进行,并且滑动2个时间单元,所以窗口操作需要两个参数:
下面是窗口操作的一个例子,假设需要在最后的30秒每10秒进行一次wordCount,代码如下(30秒作为窗口持续时间参数,10秒作为窗口操作间隔时间):
// Reduce last 30 seconds of data, every 10 seconds
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
例子中用到了reduceByKeyAndWindow操作,其他的一些常见窗口操作如下:
| 转换方法 | 意义 |
|---|---|
| window(windowLength,slideInterval) | 返回进过窗口批处理的DStream |
| countByWindow(windowLength,slideInterval) | 计算流数据中每个滑动窗口中的元素数量 |
| reduceByWindow(func,windowLength,slideInterval) | 使用func在每个窗口中计算元素的总数 |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | 每个滑动窗口中计算(K,V)中每个key的总数,返回格式为(K,V) |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | 上述方法的一个高效实现,基于上个窗口的数据进行计算 |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | 计算(K,V)返回(K,Long) |
DStream输出操作
输出操作允许DStream的数据放入外置系统如数据库或文件系统,由于输出操作需要将最终数据放入外置系统中,所以执行输出操作的时候会开始真正执行之前的转换操作。下表是一些输出操作:
| 输出操作 | 意义 |
|---|---|
| print() | 输出DStream中每批数据的前十个元素,常用于调试 |
| saveAsObjectFiles(prefix,[suffix]) | 将DStream中的内容保存为序列化的SequenceFile,每批数据产生的文件名为:prefix-TIME_IN_MS[.suffix] |
| saveAsHadoopFiles(prefix,[suffix]) | 将DStream中的内容保存为hadoop的text file,每批数据产生的文件名为:prefix-TIME_IN_MS[.suffix] |
| foreachRDD(func) | 最常见的输出操作,流中的RDD都会通过func函数处理,这个func的作用是将RDD中的数据放入外置系统如文件、数据库 |
foreachRDD的设计模式
dstream.foreachRDD是非常有用的操作,但使用它需要避免如下的几个错误:
dstream.foreachRDD(rdd => {
val connection = createNewConnection() // executed at the driver
rdd.foreach(record => {
connection.send(record) // executed at the worker
})
})
这种方式是不正确的,因为这需要将这个连接序列化以便将它从driver传送到worker中,这样的连接对象是不能在机器之间进行传送的。上面会发生序列化错误(连接对象不能被序列化)和初始化错误(连接对象需要在worker端进行初始化)等错误。正确的做法是在worker端进行创建连接对象。
dstream.foreachRDD(rdd => {
rdd.foreach(record => {
val connection = createNewConnection()
connection.send(record)
connection.close()
})
})
创建连接对象是需要时间和资源的,所以这种方式会明显的增加不必要的资源消耗和降低机器的吞吐能力,一个更好的解决方案是使用rdd.foreachPartition-创建一个单独的连接对象并且通过这个连接发送一个RDD中所有的数据:
dstream.foreachRDD(rdd => {
rdd.foreachPartition(partitionOfRecords => {
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
})
})
但这种方法在多个RDD分区中还是会创建多个连接。
dstream.foreachRDD(rdd => {
rdd.foreachPartition(partitionOfRecords => {
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
})
})
注意:池中的连接应该是根据需要记性懒式创建并且在一段时间之内不再使用需要将其释放,这种方式是最高效的。